LMAX Disruptor – High Performance, Low Latency and Simple Too
Adrian Sutton
The LMAX disruptor is an ultra-high performance, low-latency message exchange between threads. It’s a bit like a queue on steroids (but quite a lot of steroids) and is one of the key innovations used to make the LMAX exchange run so fast. There is a rapidly growing set of information about what the disruptor is, why it’s important and how it works – a good place to start is the list of articles and for the on-going stuff, follow LMAX Blogs. For really detailed stuff, there’s also the white paper (PDF).
While the disruptor pattern is ultimately very simple to work with, setting up multiple consumers with the dependencies between them can require a bit too much boilerplate code for my liking. To make it quick and easy for 99% of cases, I’ve whipped up a simple DSL for the disruptor pattern. For example, to wire up a “diamond pattern” of consumers:
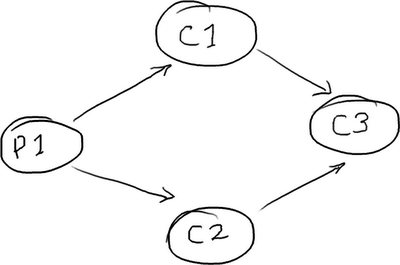
(Image blatantly stolen from Trisha Gee’s excellent series explaining the disruptor pattern)
In this scenario, consumers C1 and C2 can process entries as soon as the producer (P1) puts them on the ring buffer (in parallel). However, consumer C3 has to wait for both C1 and C2 to complete before it processes the entries. In real life this might be because we need to both journal the data to disk (C1) and validate the data (C2) before we do the actual business logic (C3).
With the raw disruptor syntax, these consumers would be created with the following code:
Executor executor = Executors.newCachedThreadPool(); BatchHandler handler1 = new MyBatchHandler1(); BatchHandler handler2 = new MyBatchHandler2(); BatchHandler handler3 = new MyBatchHandler3() RingBuffer ringBuffer = new RingBuffer(ENTRY_FACTORY, RING_BUFFER_SIZE); ConsumerBarrier consumerBarrier1 = ringBuffer.createConsumerBarrier(); BatchConsumer consumer1 = new BatchConsumer(consumerBarrier1, handler1); BatchConsumer consumer2 = new BatchConsumer(consumerBarrier1, handler2); ConsumerBarrier consumerBarrier2 = ringBuffer.createConsumerBarrier(consumer1, consumer2); BatchConsumer consumer3 = new BatchConsumer(consumerBarrier2, handler3); executor.execute(consumer1); executor.execute(consumer2); executor.execute(consumer3); ProducerBarrier producerBarrier = ringBuffer.createProducerBarrier(consumer3);
We have to create our actual handlers (the two instances of MyBatchHandler), plus consumer barriers, BatchConsumer instances and actually execute the consumers on their own threads. The DSL can handle pretty much all of that setup work for us with the end result being:
Executor executor = Executors.newCachedThreadPool(); BatchHandler handler1 = new MyBatchHandler1(); BatchHandler handler2 = new MyBatchHandler2(); BatchHandler handler3 = new MyBatchHandler3(); DisruptorWizard dw = new DisruptorWizard(ENTRY_FACTORY, RING_BUFFER_SIZE, executor); dw.consumeWith(handler1, handler2).then(handler3); ProducerBarrier producerBarrier = dw.createProducerBarrier();
We can even build parallel chains of consumers in a diamond pattern:
(Thanks to Trish for using her fancy graphics tablet to create a decent version of this image instead of my original finger painting on an iPad…)
dw.consumeWith(handler1a, handler2a); dw.after(handler1a).consumeWith(handler1b); dw.after(handler2a).consumeWith(handler2b); dw.after(handler1b, handler2b).consumeWith(handler3); ProducerBarrier producerBarrier = dw.createProducerBarrier();
The DSL is quite new so any feedback on it would be greatly appreciated and of course feel free to fork it on GitHub and improve it.